////////////////////////////////////////////////////////////////////////////
Fundamentals 5 Code Library Introduction
by Max Kleiner
“Love comes unseen; we only see it go.”
– Henry Austin Dobson
The Fundamentals 5 Code Library is a big toolbox for Delphi and FreePascal.
What I appreciate the most in this library are the main utilities for network and internet. This utilities (Utils) it provides involve math, statistic, unicode routines and data structures for classes similarly to how users would find them in a big framework. In this way, testing-routines helps ensure your tests and give you confidence in your code.
Our Test Directory includes detailed information, guides and references for many of our tests. This includes test and result codes, specimen collection requirements, specimen transport considerations, and methodology.
Concerning a documentation of the Fundamentals library, the most is detailed direct in code with a revision history and supported compilers. There are also tools like DiPasDoc which we can use to generate API documentation from comments in sources. Those are free and generates HTML as well as CHM. A very useful online docu has been built and hosted gratefully in the meantime but not finished yet:
http://fundamentals5.kouraklis.com/
David J. Butler is also the author of the Zlib version of PASZLIB which is based on the zlib 1.1.2, a general purpose data compression library.
The ‘zlib’ compression library provides in-memory compression and decompression functions, including integrity checks of the uncompressed data. This version of the library supports only one compression method
(deflation) but other algorithms will be added later and will have the same stream interface.
Similarly to for example the Indy or Jedi library, we can specify the class name, test name number of samples (measurements) to take and number of operations (iterations) the code will be executed. Most of the operations are not overload but has a strong name like that:
function GetEnvironmentVariableA(const Name: AnsiString): AnsiString;
function GetEnvironmentVariableU(const Name: UnicodeString): UnicodeString;
function GetEnvironmentVariable(const Name: String): String; {$IFDEF UseInline}inline;{$ENDIF}
Whats nice is that when you pass an empty name or something invalid as the actual parameter of samples, most of the names or buffers will be initialized and checked or fill out with a proper default name on its own.
So the Fundamentals Library includes:
String, DateTime and dynamic array routines
Unicode routines
Hash (e.g. SHA256, SHA512, SHA1, SHA256, MD5)
Integer (e.g. Word128, Word256, Int128, Int256)
Huge Word, Huge Integer
Decimal (Decimal32, Decimal64, Decimal128, HugeDecimal and signed decimals)
Random number generators
Ciphers (symmetric: AES, DES, RC2, RC4; asymmetric: RSA, Diffie-Hellman)
Data structures (array and dictionary classes)
Mathematics (Rational number, complex number, vector, matrix, statistics)
JSON parser
Google protocol buffer parser, utilities and Pascal code generator
Socket library (cross platform - Windows and Linux) TLS Client, TLS Server
TCP Client, TCP Server, HTTP Client, HTTP Server, HTML Parser and XML Parser.
https://github.com/fundamentalslib/fundamentals5/
https://github.com/maxkleiner/fundamentals5
I did open another fork on github to document my adapted scripting units. Another advantage is the use of test-procedure with assertions. It implements the Assert procedure to document and enforce the assumptions you must make when writing code. Assert is not a real procedure. The compiler handles Assert specially and compiles the filename and line number of the assertion to help you locate the problem should the assertion fail.
Assert is not a real procedure. The compiler handles Assert specially and compiles the filename and line number of the assertion to help you locate the problem should the assertion fail.
The syntax is like:
procedure Assert(Test: Boolean);
procedure Assert(Test: Boolean; const Message: string);
If you write a simple script program and distribute it to each computer, you can have the users start the tests on their own by running the script with a list of asserts.
Assert(CopyFrom(‘a’, 0) = ‘a’, ‘CopyFrom’);
Assert(CopyFrom(‘a’, -1) = ‘a’, ‘CopyFrom’);
Assert(CopyFrom(”, 1) = ”, ‘CopyFrom’);
Assert(CopyFrom(”, -2) = ”, ‘CopyFrom’);
Assert(CopyFrom(‘1234567890’, 8) = ‘890’, ‘CopyFrom’);
Assert(CopyFrom(‘1234567890’, 11) = ”, ‘CopyFrom’);
Assert(CopyFrom(‘1234567890’, 0) = ‘1234567890’, ‘CopyFrom’);
Assert(CopyFrom(‘1234567890’, -2) = ‘1234567890’, ‘CopyFrom’);
Assert(not StrMatch(”, ”, 1), ‘StrMatch’);
Assert(not StrMatch(”, ‘a’, 1), ‘StrMatch’);
Assert(not StrMatch(‘a’, ”, 1), ‘StrMatch’);
Assert(not StrMatch(‘a’, ‘A’, 1), ‘StrMatch’);
Assert(StrMatch(‘A’, ‘A’, 1), ‘StrMatch’);
Assert(not StrMatch(‘abcdef’, ‘xx’, 1), ‘StrMatch’);
Assert(StrMatch(‘xbcdef’, ‘x’, 1), ‘StrMatch’);
Assert(StrMatch(‘abcdxxxxx’, ‘xxxxx’, 5), ‘StrMatch’);
Assert(StrMatch(‘abcdef’, ‘abcdef’, 1), ‘StrMatch’);
Assert(StrMatch(‘abcde’, ‘abcd’, 1), ‘StrMatch’);
Assert(StrMatch(‘abcde’, ‘abc’, 1), ‘StrMatch’);
Assert(StrMatch(‘abcde’, ‘ab’, 1), ‘StrMatch’);
Assert(StrMatch(‘abcde’, ‘a’, 1), ‘StrMatch’);
Assert(StrMatches(‘abcd’, ‘abcd’, 1)=true, ‘StrMatches’);
Lets take the above single assert with
Function StrMatches(const Substr, S: AnsiString; const Index: Int): Boolean;
As you can see the strings matches if equal otherwise we get an Exception:
Assert(StrMatches(‘abcd’, ‘abcde’, 1)=true, ‘StrMatches’);
Exception: StrMatches
If the test condition fails the SysUtils unit sets this variable to a procedure that raises the EAssertionFailed exception.
By the way dont comment an assert like that
//Assert(StrMatchLeft(‘ABC1D’, ‘aBc1’, False), ‘StrMatchLeft’);
//Assert(StrMatchLeft(‘aBc1D’, ‘aBc1’, True), ‘StrMatchLeft’);
You can also negate an assert as long as they deliver a boolean (logic) condition:
Assert(not StrMatchLeft(‘AB1D’, ‘ABc1’, False), ‘StrMatchLeft’);
Assert(not StrMatchLeft(‘aBC1D’, ‘aBc1’, True), ‘StrMatchLeft’);
Then you want to write more assert system information to a log file for analyzing problems during installation, debugging, tests and de-installation or app distribution like that:
10/01/2018 19:31:54 V:4.6.2.10 [max] problem occurred in initializing MCI. [at: 3275216pgf; mem:1247492]
14/01/2018 17:15:18 V:4.7.2.30 [max] MAXBOX8 Out Of Range. [at: 2607048pgf; mem:1082444]
14/01/2018 17:15:21 V:4.7.2.40 [max] MAXBOX8 Out Of Range. [at: 2605716pgf; mem:1080012]
16/01/2018 09:18:00 V:4.7.5.20 [max] MAXBOX8 List index out of bounds (456). [at: 2913700pgf; mem:1157700]
{ }
{ Test cases }
{ }
{$IFDEF DEBUG}
{$IFDEF LOG}
{$IFDEF TEST}
//{$ASSERTIONS ON}
Next step is to bundle asserts in a Test Procedure with sections like that:
procedure TestBitsflc;
begin
Assert(SetBit32($100F, 5) = $102F, ‘SetBit’);
Assert(ClearBit32($102F, 5) = $100F, ‘ClearBit’);
Assert(ToggleBit32($102F, 5) = $100F, ‘ToggleBit’);
Assert(ToggleBit32($100F, 5) = $102F, ‘ToggleBit’);
Assert(IsBitSet32($102F, 5), ‘IsBitSet’);
Assert(not IsBitSet32($100F, 5), ‘IsBitSet’);
Assert(IsHighBitSet32($80000000), ‘IsHighBitSet’);
Assert(not IsHighBitSet32($00000001), ‘IsHighBitSet’);
Assert(not IsHighBitSet32($7FFFFFFF), ‘IsHighBitSet’);
Assert(SetBitScanForward32(0) = -1, ‘SetBitScanForward’);
Assert(SetBitScanForward32($1020) = 5, ‘SetBitScanForward’);
Assert(SetBitScanReverse32($1020) = 12, ‘SetBitScanForward’);
Assert(SetBitScanForward321($1020, 6) = 12, ‘SetBitScanForward’);
Assert(SetBitScanReverse321($1020, 11) = 5, ‘SetBitScanForward’);
Assert(ClearBitScanForward32($FFFFFFFF) = -1, ‘ClearBitScanForward’);
Assert(ClearBitScanForward32($1020) = 0, ‘ClearBitScanForward’);
Assert(ClearBitScanReverse32($1020) = 31, ‘ClearBitScanForward’);
Assert(ClearBitScanForward321($1020, 5) = 6, ‘ClearBitScanForward’);
Assert(ClearBitScanReverse321($1020, 12) = 11, ‘ClearBitScanForward’);
Assert(ReverseBits32($12345678) = $1E6A2C48, ‘ReverseBits’);
Assert(ReverseBits32($1) = $80000000, ‘ReverseBits’);
Assert(ReverseBits32($80000000) = $1, ‘ReverseBits’);
Assert(SwapEndian32($12345678) = $78563412, ‘SwapEndian’);
Assert(RotateLeftBits32(0, 1) = 0, ‘RotateLeftBits32’);
Assert(RotateLeftBits32(1, 0) = 1, ‘RotateLeftBits32’);
Assert(RotateLeftBits32(1, 1) = 2, ‘RotateLeftBits32’);
Assert(RotateLeftBits32($80000000, 1) = 1, ‘RotateLeftBits32’);
Assert(RotateLeftBits32($80000001, 1) = 3, ‘RotateLeftBits32’);
Assert(RotateLeftBits32(1, 2) = 4, ‘RotateLeftBits32’);
Assert(RotateLeftBits32(1, 31) = $80000000, ‘RotateLeftBits32’);
Assert(RotateLeftBits32(5, 2) = 20, ‘RotateLeftBits32’);
Assert(RotateRightBits32(0, 1) = 0, ‘RotateRightBits32’);
Assert(RotateRightBits32(1, 0) = 1, ‘RotateRightBits32’);
Assert(RotateRightBits32(1, 1) = $80000000, ‘RotateRightBits32’);
Assert(RotateRightBits32(2, 1) = 1, ‘RotateRightBits32’);
Assert(RotateRightBits32(4, 2) = 1, ‘RotateRightBits32’);
Assert(LowBitMask32(10) = $3FF, ‘LowBitMask’);
Assert(HighBitMask32(28) = $F0000000, ‘HighBitMask’);
Assert(RangeBitMask32(2, 6) = $7C, ‘RangeBitMask’);
Assert(SetBitRange32($101, 2, 6) = $17D, ‘SetBitRange’);
Assert(ClearBitRange32($17D, 2, 6) = $101, ‘ClearBitRange’);
Assert(ToggleBitRange32($17D, 2, 6) = $101, ‘ToggleBitRange’);
Assert(IsBitRangeSet32($17D, 2, 6), ‘IsBitRangeSet’);
Assert(not IsBitRangeSet32($101, 2, 6), ‘IsBitRangeSet’);
Assert(not IsBitRangeClear32($17D, 2, 6), ‘IsBitRangeClear’);
Assert(IsBitRangeClear32($101, 2, 6), ‘IsBitRangeClear’);
Assert(IsBitRangeClear32($101, 2, 7), ‘IsBitRangeClear’);
end;
{$ENDIF}
{$ENDIF}
A tester is then able to run a bunch of tests in Fundamentals, e.g:
setBitmaskTable;
TestBitsflc;
In the Fundamentals Lib we do have a 15 CLF_Fundamentals Testroutines Package:
01 TestMathClass;
02 TestStatisticClass;
03 TestBitClass;
04 TestCharset;
05 TestTimerClass
06 TestRationalClass
07 TestComplexClass
08 TestMatrixClass;
09 TestStringBuilderClass
10 TestASCII;
11 TestASCIIRoutines;
12 TestPatternmatcher;
13 TestUnicodeChar;
14 flcTest_HashGeneral;
15 flcTest_StdTypes;
procedure TestStdTypes;
begin
{$IFDEF LongWordIs32Bits} Assert(SizeOf(LongWord) = 4); {$ENDIF}
{$IFDEF LongIntIs32Bits} Assert(SizeOf(LongInt) = 4); {$ENDIF}
{$IFDEF LongWordIs64Bits} Assert(SizeOf(LongWord) = 8); {$ENDIF}
{$IFDEF LongIntIs64Bits} Assert(SizeOf(LongInt) = 8); {$ENDIF}
{$IFDEF NativeIntIs32Bits} Assert(SizeOf(NativeInt) = 4); {$ENDIF}
{$IFDEF NativeIntIs64Bits} Assert(SizeOf(NativeInt) = 8); {$ENDIF}
{$IFDEF NativeUIntIs32Bits} Assert(SizeOf(NativeUInt) = 4); {$ENDIF}
{$IFDEF NativeUIntIs64Bits} Assert(SizeOf(NativeUInt) = 8); {$ENDIF}
end;
Another way is to prevent call errors as a mistaken precondition of false assumption in
a procedure you designed. This pre- and post-condition can handle a lot of errors.
An example should make this clear.
A TStack object has a method called Pop to remove the topmost data object from the stack.
If the stack is empty, I count calling Pop as a programming mistake: you really should check for the stack being empty in your program prior to calling Pop. Of course Pop could have an if statement within it that did this check for you, but in the majority of cases the stack wont be empty when Pop is called and in the majority of cases when you use Pop, you will have some kind of loop in your program which is continually checking whether the stack is empty or not anyway. In my mind having a check for an empty stack within Pop is safe but slow.
So, instead, Pop has a call to an Assert procedure at the start (activated by the DEBUG compiler define) that checks to see whether the stack is empty. Here is the code for Pop:
function TStack.Pop : pointer;
var
Node : PNode;
begin
{$IFDEF DEBUG}
Assert(not IsEmpty, ascEmptyPop);
{$ENDIF}
Node := Head^.Link;
Head^.Link := Node^.Link;
Pop := Node^.Data;
acDisposeNode(Node);
end;
As you see, if DEBUG is set the Assert procedure checks whether the stack is empty first, if not it executes the code that pops the data object off the stack. If the stack is empty an EEZAssertionError exception is raised (the constant ascEmptyPop is a string code for a string-table resource). If DEBUG is not set the code runs at full speed.
So log the steps and compare test procedures before installation: The location of the update can be a local, UNC or network path to compare it.
When you need Admin Rights you can try this:
ExecuteShell(‘cmd’,’/c runas “/user:Administrator” ‘+
ExePath+’maXbox4.exe’)
or C:> net user Administrator /active:yes
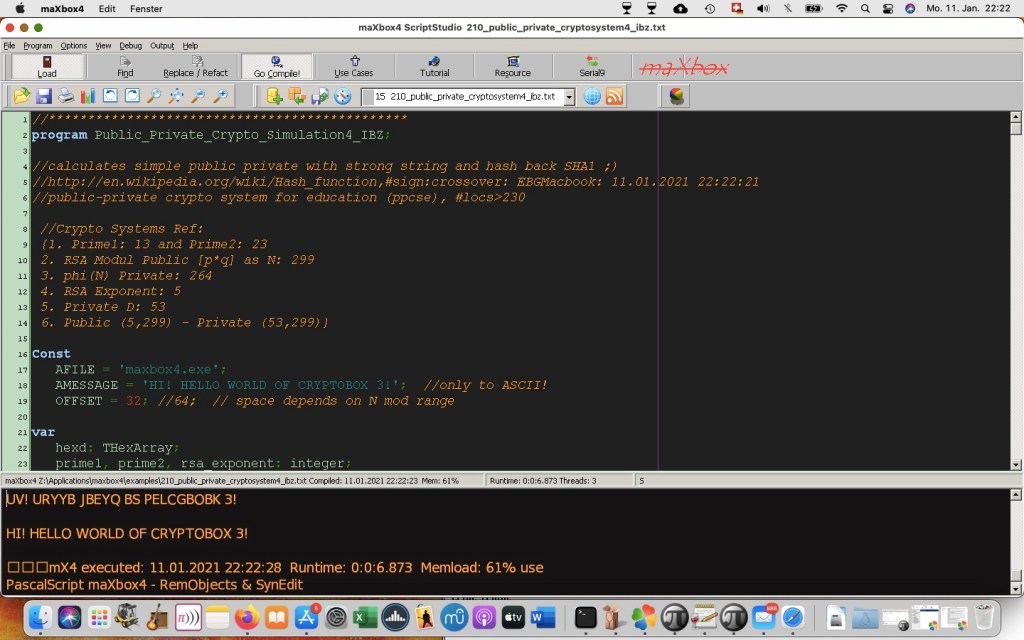
After you have finishing and writing the script, the next and final step is select “Go Compile” in maXbox. What this does is create a complete, ready-to-run Setup program based on your script. By default, this is created in a directory named Exepath under the directory or UNC path containing the script or what destination you need.
function GetInstallScript(const S_API, pData: string): string;
var ts: TStrings;
begin
with TIdHTTP.create(self) do begin
try
ts:= TStringList.Create
ts.Add('install='+HTTPEncode(pData));
result:= Post(S_API,ts);
finally
ts.Free;
Free;
end;
end
end;
The big step comes with unit tests with setup and tear down. Generic “Assert This” Assertion Procedure means that most generic assertion program simply says “assert this” and passes a Boolean expression. It is used by all the other assertion routines, which construct a Boolean expression from their specific values and logic.
Unit testing is a way of testing the smallest piece of code referred to as a unit that can be logically isolated in a system. It is mainly focused on the functional correctness of standalone modules.
A unit can be almost anything you want it to be – a specific piece of functionality, a program, or a particular method within the application:
type
THugeCardinal_TestCase = TTestCase;
var
Fbig1234: THugeCardinal;
Fbig2313: THugeCardinal;
Fbig3547: THugeCardinal;
//TVerifyResult
Temp1, Temp2, Temp3, Temp4: THugeCardinal;
Temp2000_1: THugeCardinal;
Temp2000_2: THugeCardinal;
T3, F100: THugeCardinal;
TmpStream: TMemoryStream;
procedure THugeCardinal_TestCaseSetUp; //override;
procedure THugeCardinal_TestCaseTearDown; //override;
//published
//procedure Test_CreateZero;
procedure Test_CreateRandom;
procedure Test_CreateSmall;
procedure Test_Clone;
procedure Test_Assign;
procedure Test_Zeroise;
procedure Test_CompareSmall;
procedure Test_Compare;
procedure Test_AssignSmall;
procedure Test_BitLength;
procedure Test_MaxBits;
procedure Test_Add;
procedure Test_Increment;
procedure Test_Subtract;
procedure Test_MulPower2;
procedure Test_MulSmall;
procedure Test_Multiply;
procedure Test_Modulo;
procedure Test_AddMod;
procedure Test_MultiplyMod;
procedure Test_isOdd;
procedure Test_CreateFromStreamIn;
procedure Test_CloneSized;
procedure Test_Resize;
procedure Test_AssignFromStreamIn;
procedure Test_Swap;
procedure Test_ExtactSmall;
procedure Test_StreamOut;
procedure Test_PowerMod;
procedure Test_SmallExponent_PowerMod;
procedure InitUnit_HugeCardinalTestCases;
begin
//TestFramework.RegisterTest( THugeCardinal_TestCase.Suite)
THugeCardinal_TestCaseSetUp;
end;
procedure DoneUnit_HugeCardinalTestCases;
begin
THugeCardinal_TestCaseTearDown
end;
Conclusion:
The proper way to use Assert in the Fundamentals Lib is to specify conditions that must be true in order for your code to work correctly.
Assert(StrMatches(‘abcd’, ‘abcde’, 1)=true, ‘StrMatches’);
All programmers make assumptions about internal state of an object or function, the value or validity of a subroutine’s arguments, or the value returned from a function. A good way to think about assertions is that they check for programmer errors, not user errors!
My 7 Steps for maintainable code:
• Maintain separation of concerns (avoid unnecessary dependencies)
• Fully qualified unit names to be used: Winapi.Windows not Windows
• Code format to be consistent with LIB source
• Do not put application-specific implementations in general code libraries
• Carefully consider modification to common code – the way to proceed
• No hints (instant code review fail) and No warnings
• Keep code small – avoid long methods and should be broken down
Ref:
http://www.softwareschule.ch/download/maxbox_starter36.pdf
https://github.com/fundamentalslib/fundamentals5/
http://www.softwareschule.ch/examples/unittests.txt
script: 919_uLockBox_HugeCardinalTestCases.pas
Doc:
http://fundamentals5.kouraklis.com/
https://maxbox4.wordpress.com

Machine Learning algorithms can be divided into 12 branches, based on underlying mathematical model:
- Bayesian — Bayesian machine learning models are based on Bayes theorem which is nothing but calculation of probability of something happening knowing something else has happened, e.g. probability that Yuvraj (Cricketer) will hit six sixes knowing that he ate curry-rice today. We use machine learning to apply Bayesian statistics on our data and we are assuming in these algorithms that there is some independence in our independent variables. These models start with some belief about data and then the models update that belief based on data. There are various applications of Bayesian statistics in classification as I did in my Twitter Project using Naive Bayes Classifier. Also, in business calculating probability of success of certain marketing plan based on data points and historical parameters of other marketing strategies.
- Decision Tree — Decision tree as the name suggests is used to come to a decision using a tree. It uses estimates and probabilities based on which we calculate the likely outcomes. Tree’s structure has root node which gets divided into Internal nodes and then leafs. What is there on these nodes is data classification variables. Our models learns from our labelled data and finds the best variables to split our data on so as to minimize the classification error. It can either give us classified data or even predict value for our data points based on the learning it got from our training data. Decision Tree’s are used in finance in option pricing, in Marketing and Business planning to find the best plan or the overall impact on business of various possibilities.
- Dimensional Reduction — Imagine you got data which has 1000 features or you conducted a survey with 25 questions and are having a hard time now making sense of which question is answering what. That is where the family of dimensional reduction algorithms come into picture. As the name suggests they help us in reducing the dimensions of our data which in turn reduces the over-fitting in our model and reduces high variance on our training set so that we can make better predictions on our test set. In market research survey often it is used to categorize questions into topics which can then easily be made sense of.
- Instance Based — This supervised machine learning algorithm performs operations after comparing current instances with previously trained instances that are stored in memory. This algorithm is called instance based because it is using instances created using training data. k-nearest neighbors is one such example where new location for neighbor is updated all the time based on the number of neighbors we want for our data points and it is done using the previous instance of neighbor and its position which was stored in memory. Websites recommend us new products or movies working on these instance based algorithms and mix of more crazy algorithms.
- Clustering — Making bunch of similar type of things is called clustering. The difference here is that we are clustering points based on the data we have. This is an unsupervised machine learning algorithm where algorithm itself makes sense of whatever gibberish we give it. Algorithm clusters the data based on those inputs and then we can make sense of data and find out what all things or points fit together better. Some of the business applications include bundling of products based on customer data of purchase of products. Clustering consumers on basis of their reviews about a service or product into difference categories. These insights help in business decisions.
- Regression — In statistics often we come across problems which require us to find a relationship between two variables in our data. We explore how change in one variable can affect the other variable. That is where we use regression. In these algorithms our machine tries to find the best line that can be fit into our data something similar to slope of a line. Our algorithm tries to find the line with best slope to minimize error in our data. This line can be used then by us to make predictions be it in form of values or in the form of probability
- Rule System — Rule based machine learning algorithms work on set of rules that are either predefined by us or they develop those rules themselves. These algorithms are less agile when creating a model or making predictions based on that model. But due to their less agility they are faster in doing what they are set to do. These are used to analyze huge chunks of data or even data which is constantly growing. They are also used for classification and can work faster than other classification algorithms. Accuracy might take a hit here but in machine learning its always a trade-off between accuracy and speed.
- Regularization — These techniques or algorithms are used in conjunction with regression or classification algorithms to reduce the effect of over-fitting in data. Tweaking of these algorithm allows to find the right balance between training the model well and the way it predicts. Many times we have too many variables or their effect on modelling is huge in those cases regularization works to reduce that high variance in our model.
- Ensemble — This method of machine learning combines various models to produce one optimal predictive model. They are usually better than single models as they are combining different models to achieve higher accuracy. More like a perfect life partner. Only drawback being that they might be slow in running. Sometimes when speed is required over accuracy we can switch over to rule-based algorithms or regression.
- Neural Networks — Based on the principle of working of neurons in brain, Neural networks are complex algorithms that work in layers. These layers take input from previous layer and do processing. More layers increase the accuracy but make algorithm slow. They work better than other algorithms but due to their computationally expensive characteristics did not gain popularity in past. But now they are back in business as the processors have improved. They are being used for sales forecasting, financial predictions, anomaly detection in data and language processing.
- Deep Learning — Deep learning algorithms use neural networks and constantly evolve the model they work on using new data. They learn and better themselves just like a human being would. Self-driving cars are based on these algorithms. I know what you are thinking here, it is what AI is based on. The real terminator will be based on this algorithm but we are way far away from it. There are full businesses running on deep learning algorithms. New delivery systems are under development which use these algorithms, Google’s AlphaGo is another example. Deep learning structures algorithms in layers and uses them to make decisions.
12. Classifier – Naive Bayes classifier is a classification algorithm which works on Bayes theorem. It assumes that all the features exist independent of each other. It is supervised machine learning algorithm and we need to provide both data and labels to train it.






@maxkleiner I read your article. Great stuff!
And again thanks for the mention
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub, or unsubscribe.
LikeLike
It is Netflix telling you watch this movie next, Spotify playing good songs without you touching your phone, its your keyboard in phone, it is how they predict next years sales. Machine learning in its simplest form is learning from data and then predicting or dividing it into meaning parts to make sense of it in a easier and usable fashion.
LikeLike
Classification is missing and Logistic Regression is more a classifier than regression. Logistic regression is a supervised learning classification algorithm used to predict the probability of a target variable.
LikeLike
Born from the ice, frozen in the deep – aus dem eis geboren, in der tiefe gefroren
LikeLike