
Data Science Workshop v. 28.5.2018, 13-15:30 pm
Agenda: Introduction to TensorFlow and Scikit Learn

We showed 4 building blocks and 8 discussion topics:
- Introduction (till slide 38)
- Methodology
https://www.tensorflow.org/tutorials/
- Practical Approach
C:\maXbox\mX46210\DataScience\confusionlist\mnist_softmax21.py
http://cs231n.github.io/python-numpy-tutorial/
: X:\1_Public\Documents\Data Science Workshops
- Best Introduction as Ranking
Topics Discussion:
Topics:
- – CaseCrunch UseCase
- – Start Values for Weights
- – How to change Stochastic Gradient
- – Why do you have reduce_mean()
- – Are there other classifications or what is best?
- – What is the random by RandomForest?
- – Implicit or explicit screen image classification?
- – Which TF Tutorials are available?
1.—————————————
CaseCrunch is proud to announce the results of the lawyer challenge. CaseCruncher Alpha scored an accuracy of 86.6%. The lawyers scored an accuracy of 62.3%.
Over 100 commercial London lawyers signed up for the competition and made over 750 predictions over the course of a week in an unsupervised environment.
The problems were real complaints about PPI mis-selling decided and published by the Financial Ombudsman Service under the FOIA.
The main reason for the large winning margin seems to be that the network had a better grasp of the importance of non-legal factors than lawyers.
2.———————————————-
Question about weights at the beginning
I know initializations define the probability distribution used to set the initial random weights of layers. The options gives are uniform lecun_uniform, normal, identity, orthogonal, zero, glorot_normal, glorot_uniform, he_normal, and he_uniform.
How does my selection here impact my end result or model? Shouldn’t it not matter because we are “training” whatever random model we start with and come up with a more optimal weighting of the layers anyways?
3.——————————————-
- How to change Stochastic Gradient Steps
Is the learning rate related to the shape of the error gradient, as it dictates the rate of descent?
Yes >>>
3 optimize this loss with learn rate , e.g. 0.4
train_step = tf.train.GradientDescentOptimizer(0.4).minimize(cross_entropy)
4.—————————————-
- Why do you have reduce_mean()
There are three training modes for neural networks
stochastic gradient descent: Adjust the weights after every single training example
batch training: Adjust the weights after going through all data (an epoch)
mini-batch training: Adjust the weights after going through a mini-batch. This is
usually 128 training examples.
Training for 1,000 steps means 128,000 training examples with the default # batch size. This is roughly equivalent to 5 epochs since the training dataset contains 25,000 examples.
estimator.train(input_fn=train_input_fn, steps=1000);
5.——————————————————
- Are there other classifications or what is best?
I have tried using Naive bayes on a labeled data set of crime data but got really poor results (7% accuracy). Naive Bayes runs much faster than other alogorithms I’ve been using so I wanted to try finding out why the score was so low.best?
After reading I found that Naive bayes should be used with balanced datasets because it has a bias for classes with higher frequency. Since my data is unbalanced I wanted to try using the Complementary Naive Bayes since it is specifically made for dealing with data skews.
Note that if your algorithm returns everything, it will return every relevant result possible, and thus have high recall, but have very poor precision. On the other hand, if it returns only one element, the one that it is the most certain is relevant, it will have high precision but low recall.
In order to judge such algorithms, the common metric cost function is the F-score!
- have high precision, not return irrelevant information
- have high recall, return as much relevant results as possible
6.—————————————————————–
- What is the random by RandomForest?
A: The sub-sample size is always the same as the original input sample size but the samples of a decision tree are drawn by random.
n_estimators=10 or n
Random forests or random decision forests are an ensemble learning method for classification, regression and other tasks, that operate by constructing a multitude of decision trees at training time and outputting the class that is the mode of the classes or mean prediction of the individual trees.
Also, you should be aware of the most amazing feature of random forests in Python:
instant parallelization! Those of us who started out doing this in R and then moved over are always amazed, especially when you get to work on a machine with a few dozen cores.
You can use decision tree methods, specifically Random Forests for calculating the most important attributes based on information gain if you have already found a way to identify how to label a person.
However, if you do not have any label information maybe you can use some expert view for preliminary attribute selection. After that you make unsupervised classification in order to retrieve your labels. Lastly, you can select the most important fields using Random Forest or other methods like Bayesian Belief Networks.
from sklearn.ensemble import RandomForestClassifier
y = df[“Relevance”]
X = df[features]
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X,y)
clf = RandomForestClassifier(n_estimators=10)
clf = clf.fit(X, y)
Class Map Assume 25.5.2018
their domain or source decisions:
ID Sentiment Relates KWords Topic[%] Corpus Crime Class Relevance
1 bad many 61 A small 1 Yes
2 good few 39 B medium 0 No
3 good few 82 A big 1 No
4 bad many 75 C medium 1 Yes
5 bad many 66 A big 1 Yes
6 good many 77 A small 0 Yes
7 good few 92 B big 0 No
I would recommend training on more balanced subsets of data. Training random forest on sets of randomly selected positive example with a similar number of negative samples. In particular if the discriminative features exhibit a lot of variance this will be fairly effective and avoid over-fitting.
7.——————————————————————–
- Implicit or explicit screen classification?
Best classification algorithms store the knowledge implicitly. This means, that they are not able to convert this knowledge to rules, which could be expressed explicitly in the form of if-then sentences or decision trees. If an algorithm is able to express its knowledge in explicit form, it is called ‘a machine learning algorithm’. While extracting explicit rules from large databases may be interesting in some cases, the resulting classification success using these explicit rules is usually lower then when using classifiers, which store the knowledge implicitly.
7.1 General recommendations and info on different algorithms
Naive Bayes
The veteran of classification. It will furnish best classificaiton results, regardless of the many methods introduced, especially due to the use of m-estimate of probability and Laplace-law of propability. It is very fast in learning and classification. Natively handles only discrete attributes and requires a special discretization engine for real valued attributes. The algorithm will compute probability distributions for all attributes for each class and classify in to the most probable class.
K-NN or K nearest neighbors
Another veteran of classification. Gives best classification results especially with real valued attributes. Its biggest setback is performance. The learning phase is fast, but each classification requires that all the examples are read again. (Naive Bayes requires only that all the classes are read again.) As the name suggests, the algorithm will search up K nearest neighbors and then classify in to the majority class in this selection of K neighbors.
Linear Classifier
Specifically designed to address the problems of prior probabilities of classes and is prior probability invariant. (Solves problems of majority class prevalance and differences in probability distribution of classes between acquired and test examples). As fast as Naive bayesian and also able to handle real valued attributes. It is a compromise between the speed of naive bayesian and the ability of K-NN to handle real valued attributes.
The algorithm will compute probability distributions for all attributes for each class and classify to the most probable class. Main difference to the Naive Bayes: Training one class does affect the response of other classes. This allows the response of specific classes to be hand engineered (fuzzy logic design). The response of the class is interpreted as: Average probability across all attributes, that this new example belongs to this class. We classify to the class with the strongest response.
nums2 = list(range(20))
print([x ** 2 for x in nums2])
C:\maXbox\softwareschule\MT-HS12-05\BFH2018\Release\Release\EventsML\EventsML>jupyter nbconvert “C:\maXbox\mX46210\DataScience\confusionlist\tut-text-ml2\textanalyse2cassandra.ipynb” –to python
8. TF Tutorials
- Images
- MNIST
- Image Recognition
- Image Retraining
- Convolutional Neural Networks
- Sequences
- Text Classification
- Recurrent Neural Networks
- Neural Machine Translation
- Drawing Classification
- Simple Audio Recognition
- Data Representation
- Linear Models
- Wide & Deep Learning
- Vector Representations of Words
- Kernel Methods
- Non-ML
- Mandelbrot Set
- Partial Differential Equations
http://cls.corpora.uni-leipzig.de/
Decision trees can be thought as a collection of ‘if-then’ statements. They take an input data set and try to match the output data-set through a tree-like structure of if-then statements. Each node on the tree is known as a ‘leaf’ and each leaf assigns a value in a regression tree. The algorithm finds the best place to create a split in order to minimize the loss function (error) in the actual output vs. the output the decision tree creates. This is very similar to the game of 20 questions – you have to find the best questions in order to optimize the tree for new, unseen data
http://martinsiron.com/2017/11/25/using-tensorflows-cnn-vs-sklearns-decision-tree-regressor/

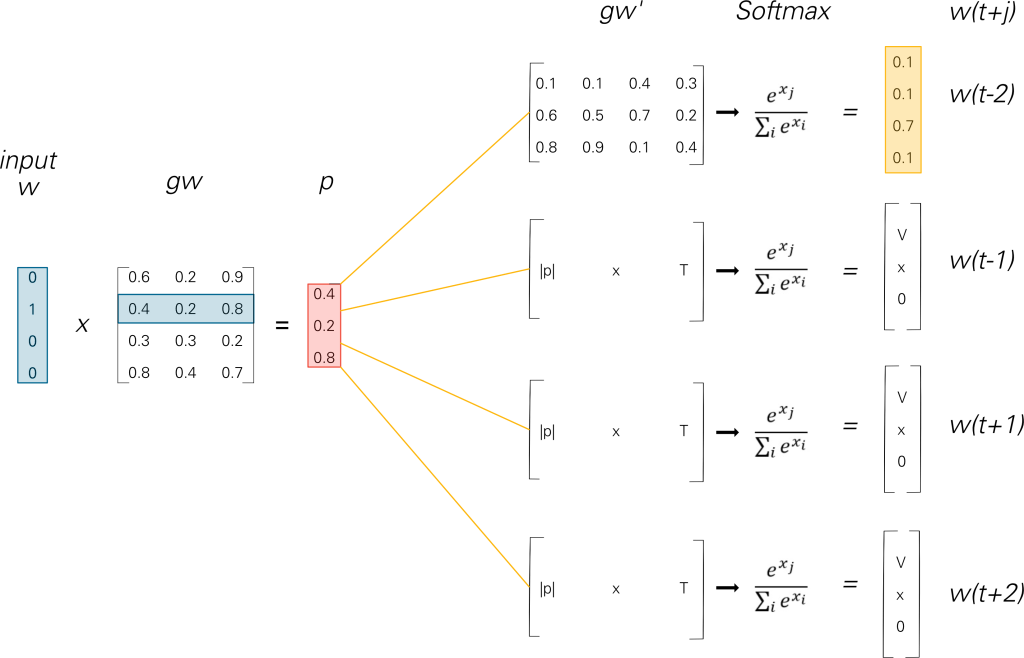
Reflection Code
FUNCTION GetIDE_Editor2maXbox3 : HWnd;
VAR W : HWnd;
ClassName : string; //ARRAY[0..32] OF Char;
BEGIN
setLength(classname,32)
W := GetWindow(FindWindow('TMaxForm1', ''), GW_Child);
WHILE W <> 0 DO BEGIN
GetClassName(W, ClassName, 32); //fix
//IF StrComp(ClassName, 'TEditControl') = 0 THEN BEGIN
IF StrComp(ClassName, 'TMemo') = 0 THEN BEGIN //TSynMemo is here
Result := W;
writeln('subclass TMemo/memo2 found');
Exit;
END;
W:= GetWindow(W, GW_HWNDNext);
END; {WHILE}
Result := 0;
MessageBeep(mb_IconInformation);
END; {F }
PROCEDURE {tCodeWizard.}InsertMessageBeep3;
VAR
S : string; //ARRAY[0..255] OF Char;
itemindex: integer;
BEGIN
itemindex:= 1;
setlength(S, 255)
//CASE MBeeps_RG1.ItemIndex OF
CASE ItemIndex OF
0 : StrCopy(S, 'MessageBeep(mb_IconInformation);'#13#10);
1 : StrCopy(S, 'MessageBeep(mb_IconExclamation);'#13#10);
2 : StrCopy(S, 'MessageBeep(mb_IconQuestion);'#13#10);
3 : StrCopy(S, 'MessageBeep(mb_IconStop);'#13#10);
4 : StrCopy(S, 'MessageBeep(0);'#13#10);
5 : StrCopy(S, 'MessageBeep(65535);'#13#10);
END; {CASE}
Spaces(S, 2);
ClipBoard.SetTextBuf(S);
SendMessage(GetIDE_Editor2maXbox3, wm_Paste, 0, 0);
//writeln('debug strcopy: '+S);
END; {PROCEDURE tCodeWizard.InsertMessageBeep}
var teststring: string;
Begin //@main
teststring:= 'maXbox4 1123_CODEWIZU.PAS Compiled done';
writeln(itoa(length(teststring)));
setlength(teststring,30)
writeln(itoa(length(teststring)));
writeln(teststring)
maxform1.memo2.color:= clgreen;
//InsertSeparatorHeader;
MaxForm1.ReadOnly1click(self); //set menu/output/read_only_output false
InsertMessageBeep3;
MaxForm1.ReadOnly1click(self); // toogle back
//MaxForm1.Savescreenshotclick(self); //
MessageBeep(mb_IconExclamation);
END.
Sends the specified message to a window or windows. The SendMessage function calls the window procedure for the specified window and does not return until the window procedure has processed the message.
To send a message and return immediately, use the SendMessageCallback or SendNotifyMessage function. To post a message to a thread’s message queue and return immediately, use the PostMessage or PostThreadMessage function.

Remove unwanted registry app:
procedure RemoveFromRunKey(ApTitle: string);
var
Reg: TRegistry;
TheKey: string;
ListOfEntries: TStringList;
i: integer;
begin
Reg:= TRegistry.Create;
Reg.RootKey:= HKEY_LOCAL_MACHINE;
TheKey := 'Software\Microsoft\Windows\CurrentVersion\Run';
// Check if key exist...
// ...if yes, try to delete the entry for ApTitle
if not Reg.OpenKey(TheKey, False) then
ShowMessage('Key not found')
else begin
if Reg.DeleteValue(ApTitle) then
ShowMessage('Removed: ' + ApTitle)
else
ShowMessage('Not found: ' + ApTitle);
end;
Reg.CloseKey;
Reg.Free;
end;

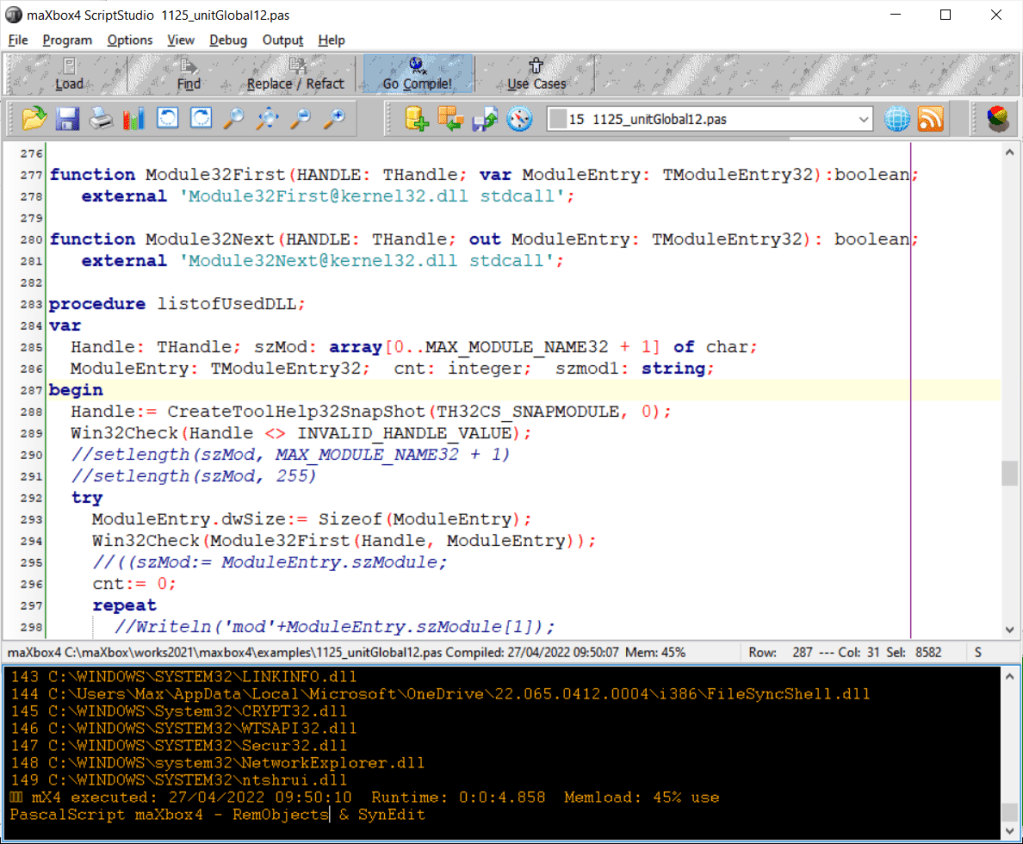
MODULEENTRY32 structure
Describes an entry from a list of the modules belonging to the specified process.
Syntax
C++
typedef struct tagMODULEENTRY32 {
DWORD dwSize;
DWORD th32ModuleID;
DWORD th32ProcessID;
DWORD GlblcntUsage;
DWORD ProccntUsage;
BYTE *modBaseAddr;
DWORD modBaseSize;
HMODULE hModule;
char szModule[MAX_MODULE_NAME32 + 1];
char szExePath[MAX_PATH];
} MODULEENTRY32;
//https://docs.microsoft.com/en-us/windows/win32/api/tlhelp32/nf-tlhelp32-module32first
function Module32First(HANDLE: THandle; var ModuleEntry: TModuleEntry32):boolean;
external 'Module32First@kernel32.dll stdcall';
function Module32Next(HANDLE: THandle; out ModuleEntry: TModuleEntry32): boolean;
external 'Module32Next@kernel32.dll stdcall';
procedure listofUsedDLL;
var
Handle: THandle; szMod: array[0..MAX_MODULE_NAME32 + 1] of char;
ModuleEntry: TModuleEntry32; cnt: integer; szmod1: string;
begin
Handle:= CreateToolHelp32SnapShot(TH32CS_SNAPMODULE, 0);
Win32Check(Handle <> INVALID_HANDLE_VALUE);
//setlength(szMod, MAX_MODULE_NAME32 + 1)
//setlength(szMod, 255)
try
ModuleEntry.dwSize:= Sizeof(ModuleEntry);
Win32Check(Module32First(Handle, ModuleEntry));
//((szMod:= ModuleEntry.szModule;
cnt:= 0;
repeat
szmod1:= '';
for it:= 3 to length(ModuleEntry.szModule) -1 do
szmod1:= szmod1 + ModuleEntry.szModule[it];
inc(cnt);
Writeln('mod: '+ itoa(cnt)+' '+szmod1);
//Writeln('procid: '+ itoa(cnt)+' '+GetModuleName(ModuleEntry.hmodule));
//GetModuleName( Module : HMODULE) :Str
until not Module32Next(Handle, ModuleEntry);
finally
CloseHandle(Handle);
end;
end;
The modBaseAddr and hModule members are valid only in the context of the process specified by th32ProcessID.
Module32First function (tlhelp32.h)
- Retrieves information about the first module associated with a process.
- A handle to the snapshot returned from a previous call to the CreateToolhelp32Snapshot function.
- The calling application must set the dwSize member of MODULEENTRY32 to the size, in bytes, of the structure.
listofUsedDLL;
List:= TStringList.Create;
if LoadedModulesList(List, getProcessID, false) then
for I:= 0 to List.Count - 1 do
writeln(itoa(i)+' '+list[i]);
list.Free;
Syntax
C++
BOOL Module32First(
[in] HANDLE hSnapshot,
[in, out] LPMODULEENTRY32 lpme
);
procedure ListDLLFunctions(DLLName: String; List: TStrings);
type
chararr = array [0..$FFFFFF] of Char;
var
H: THandle;
I, fc: integer;
st: string;
arr: Pointer;
ImageDebugInfo: PImageDebugInformation;
begin
List.Clear;
DLLName:= ExpandFileName(DLLName);
if FileExists(DLLName) then begin
H:= CreateFile(PChar(DLLName),GENERIC_READ,FILE_SHARE_READ or
FILE_SHARE_WRITE,nil,OPEN_EXISTING,FILE_ATTRIBUTE_NORMAL,0);
if H<>INVALID_HANDLE_VALUE then
try
ImageDebugInfo:= MapDebugInformation(H,PChar(DLLName),nil,0);
if ImageDebugInfo<>Nil then
try
arr:= ImageDebugInfo^.ExportedNames;
fc:= 0;
for I:= 0 to ImageDebugInfo^.ExportedNamesSize - 1 do
if chararr(arr^)[I]=#0 then begin
st:= PChar(@chararr(arr^)[fc]);
if Length(st)>0 then
List.Add(st);
if (I>0) and (chararr(arr^)[I-1]=#0) then
Break;
fc:= I + 1
end
finally
UnmapDebugInformation(ImageDebugInfo)
end
finally
CloseHandle(H)
end
end
end;
To retrieve information about other modules associated with the specified process, use the Module32Next function.
Sonar’s industry leading solution enables developers and development teams to write clean code and remediate existing code organically, so they can focus on the work they love and maximize the value they generate for businesses. Its open source and commercial solutions – SonarLint, SonarCloud, and SonarQube – support 29 programming languages. Trusted by more than 300,000 organizations globally, Sonar is considered integral to delivering better software.
SONARSOURCE – Zürich: Die Programmierplattform für Entwickler hat 412 Millionen Dollar frisches Kapital eingesammelt. Die Bewertung steige damit auf 4,7 Milliarden Dollar, wie die in Genf ansässige Firma mitteilte. Im Rahmen der Finanzierungsrunde stiegen die Finanzinvestoren Advent International und General Catalyst neu ein. Die Aktionäre Insight Partners und Permira beteiligten sich an der Geldspritze. Das Geld soll in den Ausbau des Vertriebs fließen. SonarSource-Chef Olivier Gaudin, einer der Gründer, erklärte, dass sich das Unternehmen auch auf einen Börsengang vorbereite. Das Unternehmen, zu dessen Kunden etwa IBM, Microsoft und die Google-Mutter Alphabet gehören, peilt einen Umsatz von einer Milliarde Dollar an.






Mondrian Next Art Generator
How can we capture the unpredictable evolutionary and emergent properties of nature in software? How can understanding the mathematical principles behind our physical world help us to create digital worlds like an mondrian art generator?
procedure createBitmapsampleArtist(sender: TObject);
var
Bitmap: TBitmap;
I, X, Y, W, H: Integer;
aRed, aGreen, aBlue: Integer;
afrm: TForm;
begin
afrm:= getform2(700,500,123,'FastForm Draw Paint Perform Platform PPP Mondrian2');
afrm.ondblclick:= @createBitmapsampleArtist;
Bitmap:= TBitmap.Create;
Bitmap.Width:= 700;
Bitmap.Height:= 700;
for I:= 0 to 9 do begin
X:= Random(450);
Y:= Random(430);
W:= Random(150)+ 150;
H:= Random(150)+ 50;
aRed:= Random(255);
aGreen:= Random(255);
aBlue:= Random(255);
Bitmap.Canvas.Brush.Color:= RGB(aRed, aGreen, aBlue);
Bitmap.Canvas.Rectangle(X+20, Y+30, W, H);
end;
afrm.Canvas.Draw(0, 0, Bitmap);
for I:= 0 to 3 do begin
X:= Random(450)+220;
Y:= Random(210)+220;
W:= Random(300)+ 150;
H:= Random(100)+ 50;
aRed:= Random(255);
aGreen:= Random(255);
aBlue:= Random(255);
Bitmap.Canvas.Brush.Color:= RGB(aRed, aGreen, aBlue);
Bitmap.Canvas.Rectangle(X+10, Y+20, W, H);
end;
afrm.Canvas.Draw(0, 0, Bitmap);
SaveCanvas2(afrm.canvas,Exepath+'examples\727_mondrian_randomboxartist.png')
//openFile(Exepath+'examples\randomboxartist.png')
Bitmap.Free;
end;











Mondrian2







Real


Angle Numerical Solver
function SolveNumericallyAngle(ANumericalEquation: TNumericalEquation;
ADesiredMaxError: Double; ADesiredMaxIterations: Integer {= 10}): Double;
var
lError, lErr1, lErr2, lErr3, lErr4: Double;
lParam1, lParam2: Double;
lCount: Integer;
begin
lErr1 := ANumericalEquation(0);
lErr2 := ANumericalEquation(Pi/2);
lErr3 := ANumericalEquation(Pi);
lErr4 := ANumericalEquation(3*Pi/2);
// Choose the place to start
if (lErr1 < lErr2) and (lErr1 < lErr3) and (lErr1 < lErr4) then begin
lParam1 := -Pi/2;
lParam2 := Pi/2;
end
else if (lErr2 < lErr3) and (lErr2 < lErr4) then begin
lParam1 := 0;
lParam2 := Pi;
end
else if (lErr2 < lErr3) and (lErr2 < lErr4) then begin // wp: same as above!
lParam1 := Pi/2;
lParam2 := 3*Pi/2;
end
else begin
lParam1 := Pi;
lParam2 := TWO_PI;
end;
// Iterate as many times necessary to get the best answer!
lCount := 0;
lError := $FFFFFFFF;
while ((ADesiredMaxError < 0 ) or (lError > ADesiredMaxError))
and (lParam1 <> lParam2)
and ((ADesiredMaxIterations < 0) or
(lCount < ADesiredMaxIterations)) do begin
lErr1 := ANumericalEquation(lParam1);
lErr2 := ANumericalEquation(lParam2);
if lErr1 < lErr2 then
lParam2 := (lParam1+lParam2)/2
else
lParam1 := (lParam1+lParam2)/2;
lError := MinFloat(lErr1, lErr2);
Inc(lCount);
end;
// Choose the best of the last two
if lErr1 < lErr2 then
Result := lParam1
else
Result := lParam2
end;
You have to define procedural types:
type TNumericalEquation= function(AParameter:Double):Double;
function numcalsin(AParameter: Double): Double;
begin
result:= sin(Aparameter);
end;
function numcalcos(AParameter: Double): Double;
begin
result:= cos(Aparameter);
end;
One can assign the following values to a procedural type variable: Nil, for both normal procedure pointers and method pointers. A variable reference of a procedural type, i. e. another variable of the same type. A global procedure or function address, with matching function or procedure header and calling convention.
writeln('cos test '+flots(numcalcos(0)));
writeln('cos test '+flots(numcalcos(120)));
writeln('cos test '+flots(numcalcos(3.141592653589793)));
writeln('sin test '+flots(numcalsin(6.283185307179586)));
writeln('sin test '+format('%2.16f ',[numcalsin(6.283185307179586)]));
writeln('solve num angle: '+flots(SolveNumericallyAngle(@numcalsin, 0.01, 10)));
writeln('solve num angle: '+flots(SolveNumericallyAngle(@numcalcos, 0.01, 10)));
writeln('solve num angle: '+flots(SolveNumericallyAngle(@numcalln, 0.01, 10)));
Output:
cos test 1
cos test 0.814180970526562
cos test -1
sin test -2.44921270764475E-16
sin test -0.0000000000000002
solve num angle: 6.283185307179586
solve num angle: 3.141592653589793
solve num angle: 0
mX4 executed: 13/05/2022 11:46:14 Runtime: 0:0:1.766 Memload: 46% use
https://drive.google.com/file/d/1hvHnsUL3hM2HpzGOoHrXKndYzMXHKGzW/view?usp=sharing




function GetBit(idx: Integer): Boolean;
var tmp: PChar;
begin
if idx >= size*8 then begin
Result:= False;
Exit;
end;
tmp:= PChar(data);
tmp:= tmp+(idx div 8);
Result:= (Ord(tmp^) and (1 shl (idx mod 8))) <> 0;
end;

https://aiartists.org/ai-generated-art-tools
LikeLike
Technology
Delphi is a distributed system that runs multiple machine learning algorithms on many machines across a cloud to find predictive models of optimal efficiency. It is designed to learn from its experience across a multitude of data sets and act as a recommender system that points out the most promising approach. It uses Bayesian optimization and Multi-Armed Bandit techniques for inter-model selection. It manages big data by breaking it down into smaller chunks to find optimal models on these, and then combining them into a higher performance meta-model while making use of the previously created models to enable knowledge transfer in modeling. The software has been tested with multiple data sets.
https://tlo.mit.edu/technologies/delphi-distributed-multi-model-self-learning-platform-machine-learning-big-data
LikeLike
Advances in AI are slowed down by a global shortage of workers with the skills and experience in areas such as deep learning, natural language processing and robotic process automation. So with AI technology opening new opportunities, financial services workers are eager to gain the skills they need in order to leverage AI tools and advance their careers.
LikeLike
https://blogs.embarcadero.com/why-a-data-scientist-chooses-delphi-for-powerful-real-world-visualizations/
LikeLike